3.1.3 Defining a schema and preloading data
Aside from the Ingredient table, you’re also going to need some tables that hold order and design information. Figure 3.1 illustrates the tables you’ll need, as well as the relationships between those tables.
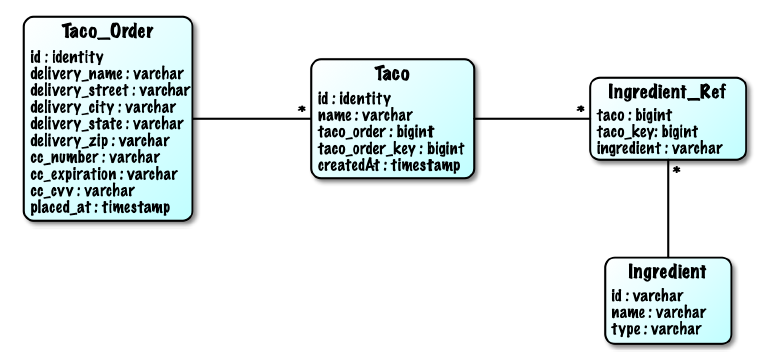 Figure 3.1 The tables of the Taco Cloud schema
Figure 3.1 The tables of the Taco Cloud schema
The tables in figure 3.1 serve the following purposes:
Taco_Order- Holds essential order detailsTaco- Holds essential information about a taco designIngredient_Ref- Contains one or more rows for each row in Taco, mapping the taco to the ingredients for that tacoIngredient- Holds ingredient information
In our application, a Taco can’t exist outside of the context of a Taco_Order. Thus, Taco_Order and Taco are considered members of an aggregate where Taco_Order is the aggregate root. Ingredient objects, on the other hand, are sole members of their own aggregate and are referenced by Taco by way of Ingredient_Ref.
NOTE:Aggregates and aggregate roots are core concepts of domain-driven design, a design approach that promotes the idea that the structure and language of software code should match the business domain. Although we’re applying a little domain-driven design (DDD) in the Taco Cloud domain objects, there’s much more to DDD than aggregates and aggregate roots. For more on this subject, read the seminal work on the subject, Domain-Driven Design: Tackling Complexity in the Heart of Software (https://www.dddcommunity.org/book/evans_2003/).
The next listing shows the SQL that creates the tables.
Listing 3.9 Defining the Taco Cloud schema
create table if not exists Taco_Order (
id identity,
delivery_Name varchar(50) not null,
delivery_Street varchar(50) not null,
delivery_City varchar(50) not null,
delivery_State varchar(2) not null,
delivery_Zip varchar(10) not null,
cc_number varchar(16) not null,
cc_expiration varchar(5) not null,
cc_cvv varchar(3) not null,
placed_at timestamp not null
);
create table if not exists Taco (
id identity,
name varchar(50) not null,
taco_order bigint not null,
taco_order_key bigint not null,
created_at timestamp not null
);
create table if not exists Ingredient_Ref (
ingredient varchar(4) not null,
taco bigint not null,
taco_key bigint not null
);
create table if not exists Ingredient (
id varchar(4) not null,
name varchar(25) not null,
type varchar(10) not null
);
alter table Taco
add foreign key (taco_order) references Taco_Order(id);
alter table Ingredient_Ref
add foreign key (ingredient) references Ingredient(id);The big question is where to put this schema definition. As it turns out, Spring Boot answers that question.
If there’s a file named schema.sql in the root of the application’s classpath, then the SQL in that file will be executed against the database when the application starts. Therefore, you should place the contents of listing 3.8 in your project as a file named schema.sql in the src/main/resources folder.
You also need to preload the database with some ingredient data. Fortunately, Spring Boot will also execute a file named data.sql from the root of the classpath when the application starts. Therefore, you can load the database with ingredient data using the insert statements in the next listing, placed in src/main/resources/data.sql.
Listing 3.10 Preloading the database wiht data.sql
delete from Ingredient_Ref;
delete from Taco;
delete from Taco_Order;
delete from Ingredient;
insert into Ingredient (id, name, type)
values ('FLTO', 'Flour Tortilla', 'WRAP');
insert into Ingredient (id, name, type)
values ('COTO', 'Corn Tortilla', 'WRAP');
insert into Ingredient (id, name, type)
values ('GRBF', 'Ground Beef', 'PROTEIN');
insert into Ingredient (id, name, type)
values ('CARN', 'Carnitas', 'PROTEIN');
insert into Ingredient (id, name, type)
values ('TMTO', 'Diced Tomatoes', 'VEGGIES');
insert into Ingredient (id, name, type)
values ('LETC', 'Lettuce', 'VEGGIES');
insert into Ingredient (id, name, type)
values ('CHED', 'Cheddar', 'CHEESE');
insert into Ingredient (id, name, type)
values ('JACK', 'Monterrey Jack', 'CHEESE');
insert into Ingredient (id, name, type)
values ('SLSA', 'Salsa', 'SAUCE');
insert into Ingredient (id, name, type)
values ('SRCR', 'Sour Cream', 'SAUCE');Even though you’ve only developed a repository for ingredient data, you can fire up the Taco Cloud application at this point and visit the design page to see JdbcIngredientRepository in action. Go ahead … give it a try. When you get back, you’ll write the repositories for persisting Taco and TacoOrder data.